Python动态获取一个城市天气信息
导入第三方库
import requests
from bs4 import BeautifulSoup
import json定义函数动态获取城市名以及编码
将拿到的城市名以及编码存入字典info中
def get_city_code(src, headers, info):
# 异常处理
try:
r = requests.get(url=src, headers=headers)
r.raise_for_status()
content = r.content.decode('utf-8')
cityData = content[len('var city_data = '):-1]
cityData = json.loads(cityData)
for c in cityData.keys():
for cy in cityData[c].keys():
for district in cityData[c][cy].keys():
code = cityData[c][cy][district]['AREAID']
name = cityData[c][cy][district]['NAMECN']
info[name] = str(code)
except:
print("出错了!!!")传入参数:
src: 请求的url链接
info:字典
headers:请求头信息(处理针对请求头反爬操作,不写会直接告诉链接我是以爬虫请求)
不写:
写入headers: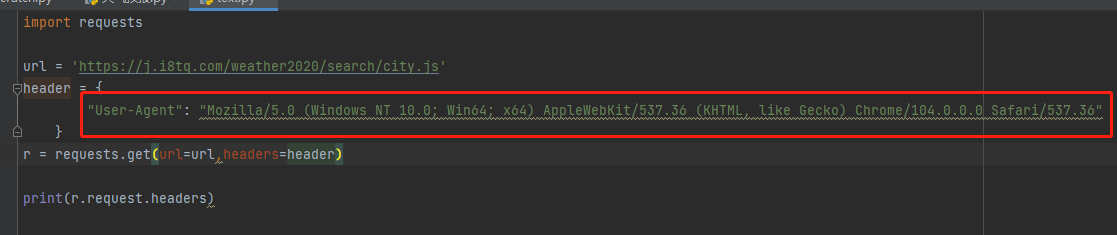

定义函数对主页面发起请求
def getHTML(src, headers):
try:
r = requests.get(url=src, headers=headers)
r.encoding = r.apparent_encoding
return r.text
except:
print("出错了!!!")获取页面的详细内容
使用的是BeautifulSoup,推荐使用xpath(需要安装lxml库),能力优秀推荐结合正则使用
pip install lxml(安装anaconda不需要再安装lxml,anaconda自带)
xpath与BeautifulSoup
区别:
1.性能lxml >> BeautifulSoup
2.易用性 BeautifulSoup >> lxml
BeautifulSoup用起来简单,API人性化,支持css选择器
lxml的XPath写起来麻烦,开发效率较低
详细使用与区别可以参考:Python爬虫之解析库的使用(XPath、Beautiful Soup)
# 获取天气详细内容
def parser_html(text):
soup = BeautifulSoup(text, 'html.parser')
sky1 = soup.find('p', class_='tem').text
weather = soup.find('p', class_='wea').text
sunUp = soup.find('p', class_='sun sunUp').text
sunDown = soup.find('p', class_='sun sunDown').text
sky1 = sky1.strip('\n')
sky2 = soup.find_all('p', class_='tem')[1].text
sky2 = sky2.strip('\n')
sunUp = sunUp.strip('\n')
sunDown = sunDown.strip('\n')
cityName = soup.find('div', class_='crumbs fl').text
cityName = cityName.replace('\n','')
cityName = cityName.replace(' ','')
print('城市:{}\n白天温度:{}\n夜晚温度:{}\n天气:{}\n{}\n{}'.format(cityName, sky1, sky2, weather, sunUp, sunDown))
程序入口
if __name__ == '__main__':
# 城市编码字典
cityInfo = {}
city_code_url = 'https://j.i8tq.com/weather2020/search/city.js'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
while True:
city = input("请输入查找的城市名:")
get_city_code(city_code_url, header, cityInfo)
city_code = cityInfo.get(city, 0)
if city_code == 0:
print("您输入的城市不存在!请从新输入!")
else:
url = 'http://www.weather.com.cn/weather1d/' + str(city_code) + '.shtml'
html = getHTML(url, header)
parser_html(html)
break全部代码
import requests
from bs4 import BeautifulSoup
import json
# 发起主页面请求
def getHTML(src, headers):
try:
r = requests.get(url=src, headers=headers)
r.encoding = r.apparent_encoding
return r.text
except:
print("出错了!!!")
# 获取天气详细内容
def parser_html(text):
soup = BeautifulSoup(text, 'html.parser')
sky = soup.find('p', class_='tem').text
weather = soup.find('p', class_='wea').text
sunUp = soup.find('p', class_='sun sunUp').text
sunDown = soup.find('p', class_='sun sunDown').text
sky = sky.strip('\n')
sunUp = sunUp.strip('\n')
sunDown = sunDown.strip('\n')
cityName = soup.find('div', class_='crumbs fl').text
cityName = cityName.replace('\n','')
cityName = cityName.replace(' ','')
print('城市:{}\n温度:{}\n天气:{}\n{}\n{}'.format(cityName, sky, weather, sunUp, sunDown))
# 获取城市编码
def get_city_code(src, headers, info):
try:
r = requests.get(url=src, headers=headers)
r.raise_for_status()
content = r.content.decode('utf-8')
cityData = content[len('var city_data = '):-1]
cityData = json.loads(cityData)
for c in cityData.keys():
for cy in cityData[c].keys():
for district in cityData[c][cy].keys():
code = cityData[c][cy][district]['AREAID']
name = cityData[c][cy][district]['NAMECN']
info[name] = str(code)
except:
print("出错了!!!")
if __name__ == '__main__':
# 城市编码字典
cityInfo = {}
city_code_url = 'https://j.i8tq.com/weather2020/search/city.js'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
while True:
city = input("请输入查找的城市名:")
get_city_code(city_code_url, header, cityInfo)
city_code = cityInfo.get(city, 0)
if city_code == 0:
print("您输入的城市不存在!请从新输入!")
else:
url = 'http://www.weather.com.cn/weather1d/' + str(city_code) + '.shtml'
html = getHTML(url, header)
parser_html(html)
break
运行结果
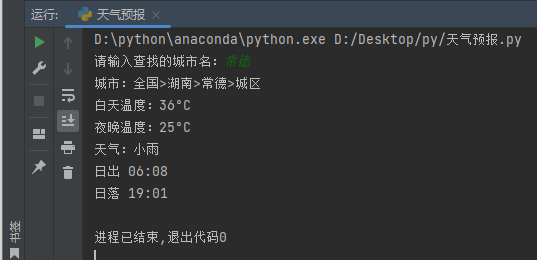
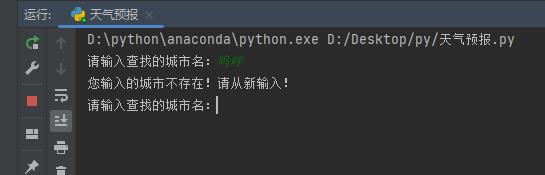
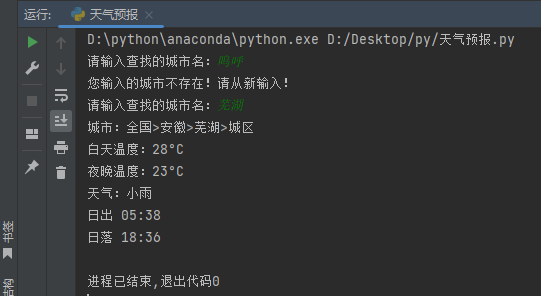
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
666